
Evo 2与津渡生科GeneLLM™共启生物科学的大模型时刻
2025 年 2 月 19 日,基础生物学模型 Evo 2 正式发布后便在生物科学界引发强烈反响,成为当前规模最大的生物学 AI 模型。该模型基于超过 12.8 万个基因组数据、9.3 万亿核苷酸序列进行训练,由非营利性 Arc 研究所与斯坦福大学牵头,与 UC Berkeley、UCSF、Liquid AI 以及 Goodfire 等单位携手,在 NVIDIA 超算集群上协同开发,共同推动生物科学底层研究范式的重构。

Evo 2 概念图,图源:Github/Evo 2
Evo 2 的开源与应用标志着生成式生物学迈入一个崭新的科学革命性阶段,实现了“用核苷酸语言来读、写和思考”的目标,使研究者无需任务特定微调,仅依靠“零样本预测”便可获得类似 DeepSeek 的前沿分析能力。与此同时,作为国内首家专注于生物科学 AI 底层大模型的企业,津渡生科也正站在这场科学革命的风暴眼,同样手握开启万亿级市场的创新密钥。
Evo 2 与 GeneLLM™:不同生物数据层次的模型
Evo 2 和 GeneLLM™ 虽然都属于生物科学大模型,但两者在本质上存在显著差异。Evo 2 的训练数据是按物种分类的基因组信息,而 GeneLLM™ 则专注于个体原始数据(如测序数据、质谱数据等)的直接训练与分析。从数据特性来看,人类参考基因组仅有一套,每个物种的基因组也相对固定,而测序数据则具有高度的多样性和个体特异性。例如,每个人的测序数据可以生成大量个体差异信息,这使得GeneLLM™ 能够深入解析人与人之间的差异,如疾病易感性、表型特征等,并精准识别“疾病相关标志物”。我们还能够在同一物种内部挖掘性状特异性的特征,例如水稻抗倒伏基因的鉴定。这种差异决定了 GeneLLM™ 与 Evo 2 在应用场景上的独立性。
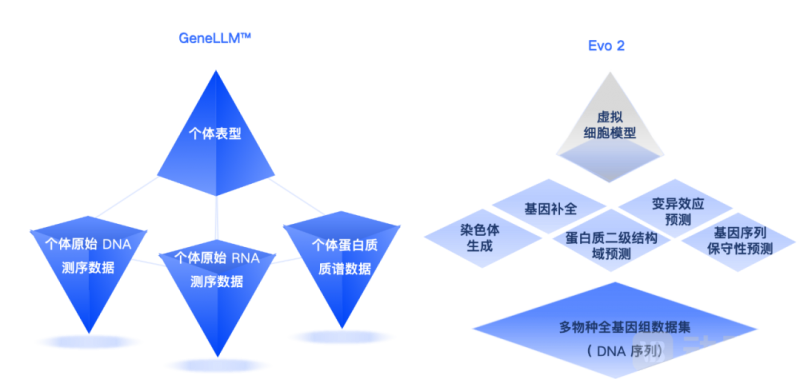
GeneLLM™ 和 Evo 2 对比图
截至目前,市场上尚未出现与GeneLLM™ 类似的、直接基于原始数据训练的模型,因为原始数据的规模更加庞大、复杂度更高,训练难度也显著更大。这种技术路径的选择使津渡生科相对于 Evo 2 在生物科学的基础研究应用,比如疾病风险评估、动植物植物性状解析等领域具备了独特的优势。
Evo 2 —— 生成式生物学 AI 的 DeepSeek 时刻
中心法则与进化论构成了从基因到种群的生物学统一理论,通过 DNA 所传递的基础信息揭示了自然选择的功能效应。Evo 系列模型正是在这一理论框架下诞生,旨在以统一的多尺度表征整合生物多样性,从分子到系统层面构建坚实的建模与设计基础。
部署于 NVIDIA BioNeMo 平台的 Evo 2 采用 StripedHyena 混合架构,其在处理百万级碱基对序列时相较于传统 Transformer 结构实现了近 3 倍的提速。同时,Evo 2 基于 DNA 序列进行自适应学习,能够对 DNA、RNA 与蛋白质功能效应进行精准预测,并覆盖中心法则(DNA → RNA → 蛋白质)的分子层级。
该模型无需任务特定微调,即可利用零样本预测高效评估变异效应。例如准确推断遗传变异在临床上对BRCA1 基因的影响,从非编码区域判断致病性。此外,Evo 2 还能自主识别外显子与内含子边界、转录因子结合位点、蛋白质结构及前噬菌体基因组区域,并具备生成符合生物学逻辑的线粒体基因组、最小细菌基因组及完整酵母染色体的能力,其生成结果在自然度与连贯性上均优于先前方法。
多领域预训练与广泛应用前景
Evo 2 模型在涵盖植物、动物与细菌等多种生物领域的预训练中表现出色,具备在医疗保健、农业生物技术及材料科学等多个科研领域的广泛应用前景。
在医疗与药物研发领域,Evo 2 能协助研究人员识别与特定疾病相关的基因变异,进而支持新型靶点的药物设计。例如,在对乳腺癌相关BRCA1 基因变体的测试中,模型在零样本预测下 AUROC 超过 0.90,而在监督模式下达到了 0.95,对良性与致病突变的区分能力表现出色。如此高效且精准的能力,正为生物医学研究带来颠覆性创新。
通用能力与未来虚拟细胞模型构想
Evo 2 的能力远不止这些。它的最大亮点在于非常灵活通用,不局限于某个具体任务,而是能在从分子到整个基因组,甚至更复杂的系统层面上,进行广泛的预测和生成新内容。

生命各领域的基因组生成规模,图源:Evo 2 preprint
其训练数据集 OpenGenome 2 基于 12.8 万个基因组构建,横跨 40 亿年进化历史,堪称数字生物博物馆,包含 9.3 万亿核苷酸的超级语料库,使模型能够捕捉从古菌甲烷代谢到人类免疫系统等众多进化密码。
团队下一步计划是将这一统一表征与表观基因组学、转录组学等多模态数据相融合,构建能够模拟健康与疾病状态下复杂细胞表型的虚拟细胞模型,为生物学研究提供更加全面的解析工具。
津渡生科 GeneLLM™——创新的生物科学人工智能研究路径
不可否认,生物系统由碳原子、氨基酸、核苷酸、蛋白质、大分子、细胞、组织与器官构成,每一层次都蕴含尚未完全阐明的“暗物质”,使得传统自下而上的建模方法容易因各层模型误差累积而偏离真实生物系统的复杂性,同时生物系统的涌现性特征也使其整体行为难以用单一层次的模型解释。
针对这一局限,津渡生科创始团队自项目伊始便另辟蹊径,率先布局生物科学人工智能赛道。GeneLLM™通过直接解析原始测序数据,并端到端输出疾病表征相关性分析,规避了分层建模中的误差叠加问题,为生物科学研究领域提供了一种全新的、切实可行的技术路径。
GeneLLM™:从单一模态生成式 AI 预测向多组学整合分析范式 AI 的跃迁
Evo 2 的核心设计理念在于:所有生物编码序列均遵循统一结构,即以起始密码子开启、以终止密码子结束。基于这一原理,Evo 2 能够通过学习序列特征,实现生成式预测下一个碱基对,也可以对未知基因的结构和功能进行预测和注释。
而 GeneLLM™在遵循相同中心法则和进化论的基础上,突破性地采用更高阶的技术实现路径——将原始测序数据直接输入模型,通过深度学习算法,GeneLLM™捕捉多组学数据的微小差异,构建疾病表征与原始数据之间的直接关联性映射。这种方法以高维数据表示和非线性关系建模为核心,显著提升了疾病预测的准确性,为生物医学研究提供了一种高效创新的研究范式。
从数据洞察到科研转化的实践路径
借助从海量原始数据中提炼洞见并直接应用于下游研究的能力,GeneLLM™已率先实现了从多组学诊断基础模型向精准医疗与基础科研转化的突破。
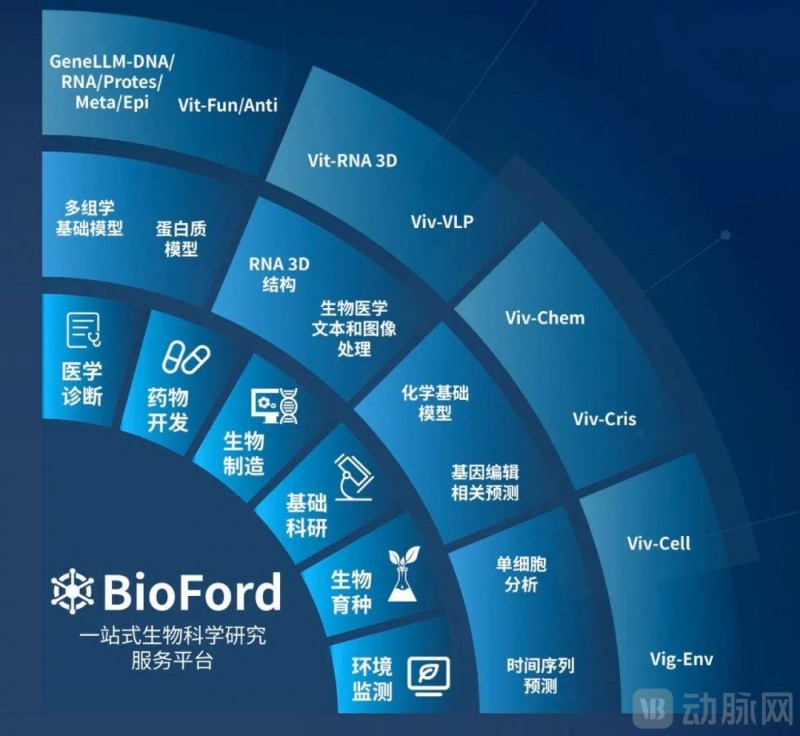
以 GeneLLM™为核心构建的一站式生物科学研究平台 Bioford™,现已整合上百个垂直生物科学领域模型,支持基因组、转录组、蛋白质、RNA 三维结构、生物医学图像及文本数据等多模态数据的全面智能分析,以满足生物医学、生物信息学、分子生物学、免疫学以及分子动力学等各学科的研究需求。平台聚焦基础科研、医学诊断、生物制造、环境监测、生物育种及药物开发六大核心场景,提供从实验室数据处理、小样本训练到模型微调及推理服务的完整解决方案。
为满足科研领域对数据隐私与安全的高标准要求,Bioford™同时支持云端与本地同步部署,并内置项目级数据保密管理系统。该方案不仅充分保障了数据完整性与机密性,更构建了一个高效、协同且安全的科研生态系统,为医院临床与高校科研在推动前沿突破及临床转化中提供了坚实保障。
开创全新赛道:GeneLLM™引领生物科学 AI 研究
生物医学研究正步入新时代。GeneLLM™的技术突破不仅颠覆了传统多组学数据分析模式,更重要的是开启了一种直接基于原始数据的全新研究范式。
充分利用人工智能“黑盒”优势的这一方法,能够捕捉到传统手段难以发现的疾病特征及生物学规律。凭借 Evo 2 的广泛突破及市场反响,津渡生科对全面实现技术破局充满信心。作为国内首家聚焦生物科学 AI 大模型的企业,津渡生科不仅在技术上与国际接轨,更通过本土化创新不断填补市场空白。
与代表生成式生物学革命的 Evo 2 相比,GeneLLM™在生物科学人工智能赛道,为全球研究人员提供了一款极具竞争力的工具,推动科学发现与产业应用双向进步。展望未来,GeneLLM™的广泛应用将助力构建一个以 AI 驱动的生物科学生态系统,覆盖医疗、农业与环境等多个领域,为人类健康与可持续发展贡献中国智慧。
关于津渡生科
津渡生科致力于提供一站式 AI 生物科学研究解决方案,其自主研发的多组学大模型 GeneLLM™ 已完成 15 亿参数和 3.5 万亿碱基序列的预训练版本。基于 GeneLLM™,津渡生科打造一站式科学服务平台 BioFord™️ ,聚焦医学诊断、药物开发、生物制造、基础科研,生物育种及环境监测六大核心场景。BioFord™平台包含九大生物科学模型库:多组学基础模型、蛋白质模型、RNA 三维结构预测模型、生物医学文本处理模型、生物医学图像处理模型、化学基础模型、CRISPR 相关预测模型、单细胞分析模型和时间序列预测模型,为科研和产业用户提供先进的 “AI for BioScience” AI 生信计算服务、云平台服务和推理一体机,已服务于华大基因、百度飞桨、协和肿瘤医院、上海交通大学医学院附属上海儿童医学中心、中国环境科学院等国内领先机构。津渡生科在深圳、北京布局研发中心,创始团队由四位牛津校友领衔,汇集了人工智能、生物信息、生物工程等领域的顶尖科学家和工程师,在《Nature》《Nature Communications》等顶级期刊发表论文六十余篇。以“ AI 科技探索生命之谜”为使命,津渡生科将继续突破 AI+ 生物科学的技术边界,为生物科学研究与产业化应用提供创新动力,助力国家科技创新与产业升级。
